
🔥 News
2024:
-
2024.12: 🎉🎉 Our research project, GeoX, has been officially open-sourced today. It is the first to explore formalized visual-language pre-training in enhancing geometric problem-solving abilities.
-
2024.10: 🎉🎉 Grateful for the heartfelt recognition and thoughtful sharing of my research work Fudan_CYL and Fudan_SIST .
-
2024.10: 🎉🎉 The technical report for MinerU, an open-source solution for high-precision document content extraction, has been published.
-
2024.09: 🎉🎉 Three papers accepted to NeurIPS 2024: AdaptiveDiffusion, ZOPP, LeapAD
-
2024.09: 🎉🎉 Previous evaluation metrics for Formula and Table Recognition tasks, such as BLEU and Edit Distrance, exhibit limitations. Our CDM has been released to ensure the evaluation objectivity by designing an image-level rather than LaTex-level metric score for Formula and Table Recognition evaluation.
-
2024.08: 🎉🎉 Bo Zhang was invited to serve as a PC member of AAAI 2025.
-
2024.08: 🎉🎉 We open-sourced StructTable: Table Structural Extraction Model Models and StructEqTable-Deploy. It is a open-source repository to support the structuring tasks of visual tables.
-
2024.08: 🎉🎉 We collaborated with the OpenDataLab team to open-source the PDF-Extract-Kit. It can extract high-quality and structured content from PDFs and has gained 6K+ stars.
-
2024.07: 🎉🎉 One paper (Reg-TTA3D) is accepted by ECCV 2024. We explore test-time adaptive 3d object detection for the first time.
-
2024.03: 🎉🎉 One paper is accepted by ACL 2024. We propose All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models.
-
2024.02: 🎉🎉 One paper (Once for Both) is accepted by CVPR 2024. Once for Both: Single Stage of Importance and Sparsity Search for Vision Transformer Compression.
-
2024.01: 🎉🎉 One paper (ReSimAD) is accepted by ICLR 2024. We propose a zero-shot generalization framework by reconstructing mesh and simulating target point clouds.
-
2024.01: 🎉🎉 Two papers (IPNet and MVNet) are accepted by TCSVT.
2023:
-
2023.12: 🎉🎉 We have released the ChartX benchmark, covering 18 chart types, 7 chart tasks, 22 disciplinary topics to evaluate the chart-related capabilities of the existing MLLMS.
-
2023.09: 🎉🎉 StructChart: our research on visual chart, has been released arXiv paper, where we will release the SimChart9K dataset powered by LLM. By the proposed SimChart9K, we observe that StructChart continuously improves the chart perception performance as more simulated charts are used for pre-training.
-
2023.09: 🎉🎉 SPOT, showing a promising and scalable 3D pre-training on autonomous driving, has been released (See our paper for more details, arXiv paper).
-
2023.09: 🎉🎉 - One paper entitled “AD-PT: Autonomous Driving Pre-Training with Large-scale Point Cloud Dataset” is accepted by NeurIPS-2023.
-
2023.07: 🎉🎉 One paper about cross-domain background-fouced alignment "Rethinking Cross-Domain Pedestrian Detection: A Background-Focused Distribution Alignment Framework for Instance-Free One-Stage Detectors" is accepted by TIP.
-
2023.07: 🎉🎉 One paper entitled "SUG: Single-dataset Unified Generalization for 3D Point Cloud Classification" is accepted by ACM MM-2023.
-
2023.04: 🎉🎉 One paper entitled "Performance-aware Approximation of Global Channel Pruning for Multitask CNNs" is accepted for publication in T-PAMI.
-
2023.03: 🎉🎉 Three papers are accepted by CVPR-2023: Uni3D, Bi3D, GDP.
-
2023.02: 🎉🎉 Bo Zhang started to work on exploring how to improve the problem-solving and reasoning ability of LLMs or VLMs for complicated modalities, including Chart, Table, Geometry, Scientific Document, by investigating foundation LLM models from the perspective of structured knowledge-rich data.
📝 Selected Publications

How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, Ji Ma, Jiaqi Wang, Xiaoyi Dong, Hang Yan, Hewei Guo, Conghui He, Botian Shi, Zhenjiang Jin, Chao Xu, Bin Wang, Xingjian Wei, Wei Li, Wenjian Zhang, Bo Zhang, Pinlong Cai, Licheng Wen, Xiangchao Yan, Min Dou, Lewei Lu, Xizhou Zhu, Tong Lu, Dahua Lin, Yu Qiao, Jifeng Dai, Wenhai Wang
- Propose InternVL 1.5 and InternVL 2. (Rank 1st among open-source VLM models on MMMU, DocVQA, ChartQA, and MathVista.)
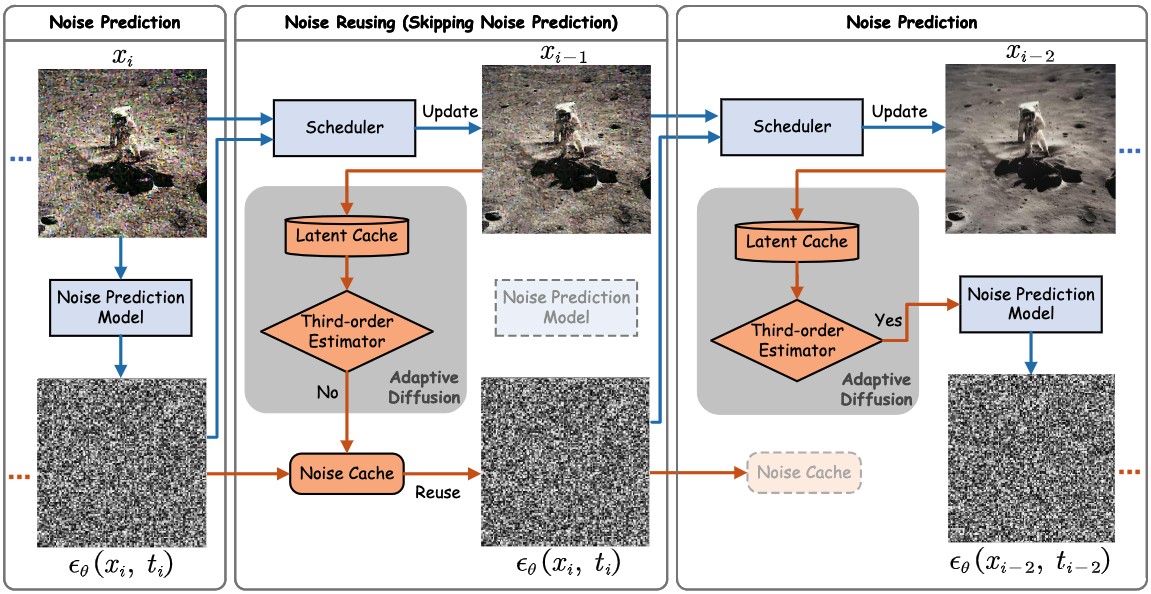
Training-Free Adaptive Diffusion with Bounded Difference Approximation Strategy
Hancheng Ye, Jiakang Yuan, Renqiu Xia, Xiangchao Yan, Tao Chen, Junchi Yan, Botian Shi, Bo Zhang^(corr.)
- Propose AdaptiveDiffusion to adaptively reduce the noise prediction steps during the denoising proces guided by the third-order latent difference.
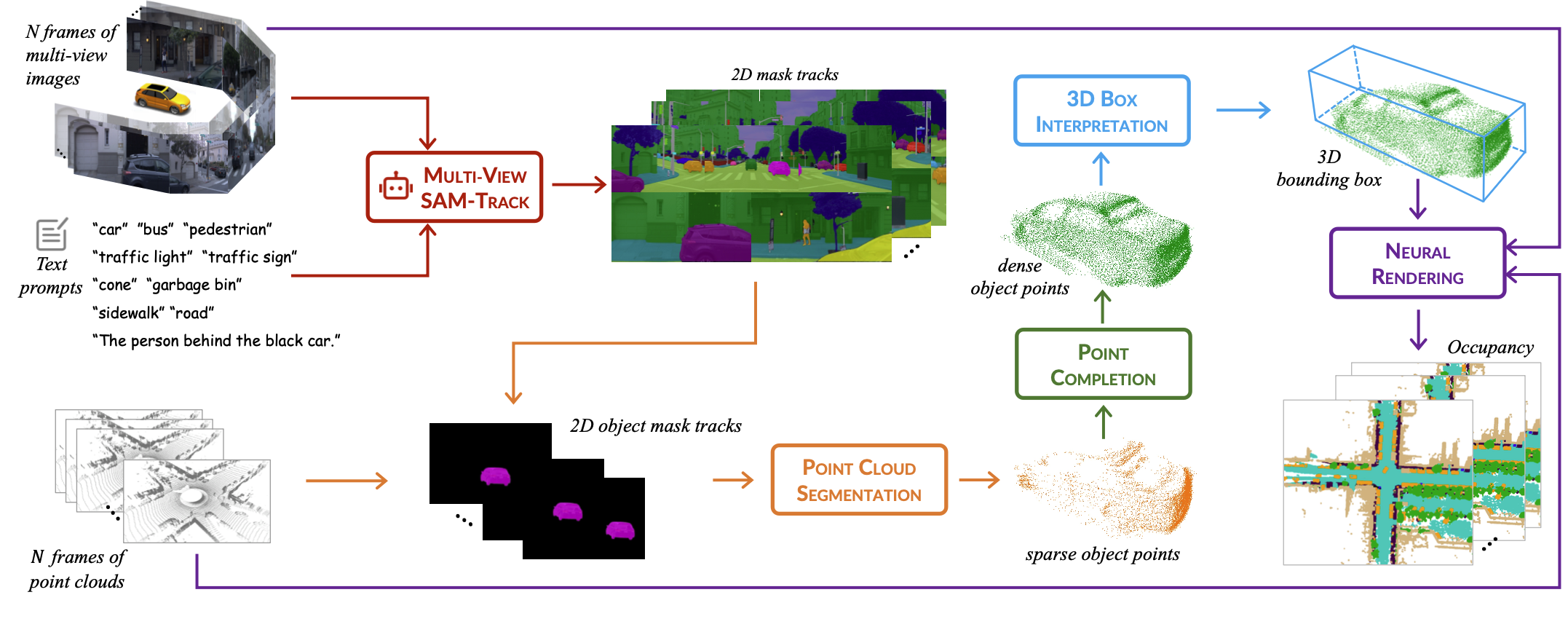
ZOPP: A Framework of Zero-shot Offboard Panoptic Perception for Autonomous Driving
Tao Ma, Hongbin Zhou, Qiusheng Huang, Xuemeng Yang, Jianfei Guo, Bo Zhang, Min Dou, Yu Qiao, Botian Shi, Hongsheng Li
- ZOPP integrates the powerful zero-shot recognition capabilities of vision foundation models and 3D representations derived from point clouds.

Continuously Learning, Adapting, and Improving: A Dual-Process Approach to Autonomous Driving
Jianbiao Mei, Yukai Ma, Xuemeng Yang, Licheng Wen, Xinyu Cai, Xin Li, Daocheng Fu, Bo Zhang, Pinlong Cai, Min Dou, Botian Shi, Liang He, Yong Liu, Yu Qiao
- LeapAD incorporates an innovative dual-process decision-making module, which consists of an Analytic Process (System-II) for thorough analysis and reasoning, along with a Heuristic Process (System-I) for swift and empirical processing.
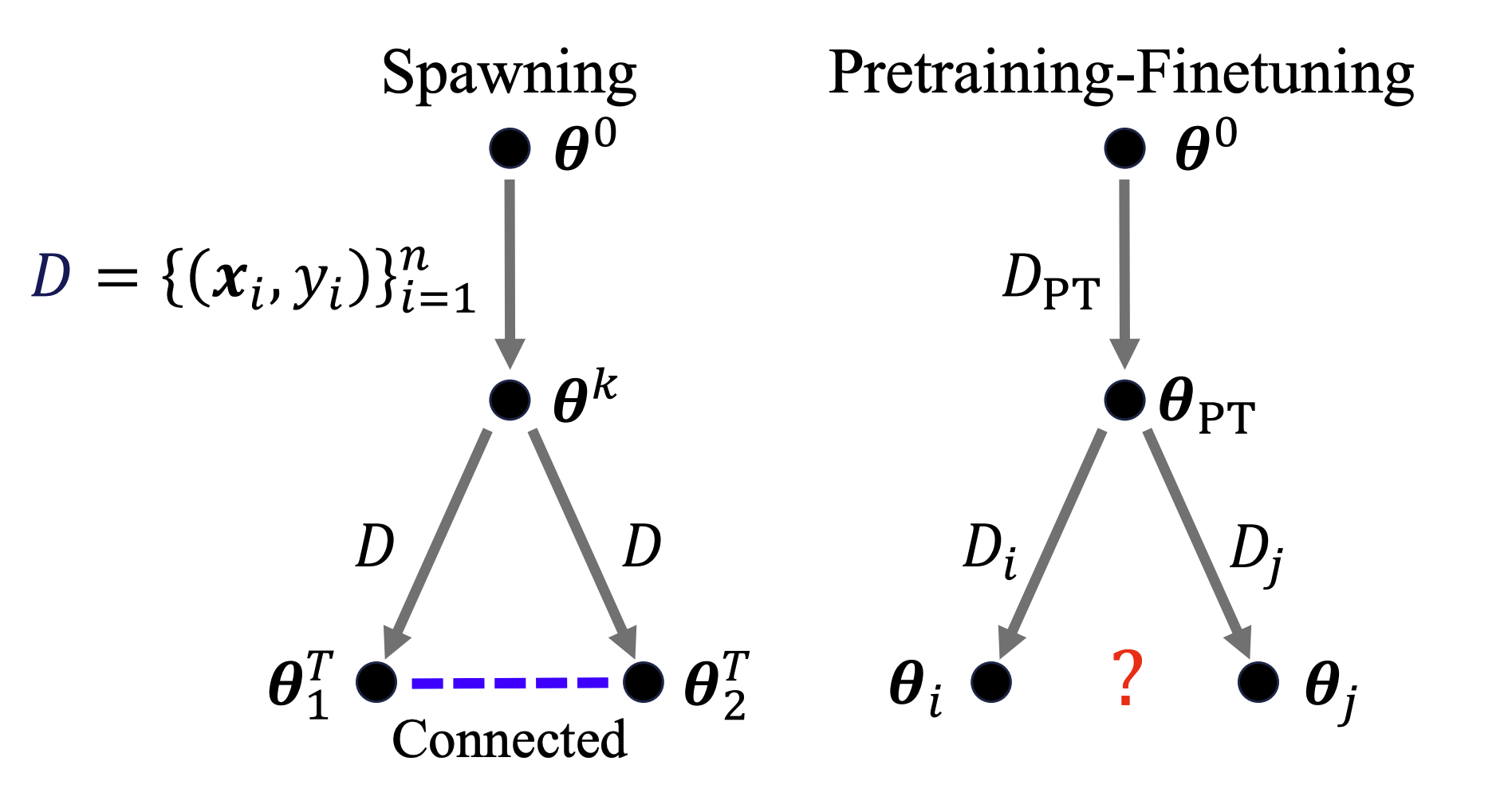
On the Emergence of Cross-Task Linearity in the Pretraining-Finetuning Paradigm
Zhanpeng Zhou, Zijun Chen, Yilan Chen, Bo Zhang^(corr.), Junchi Yan
- We discover an intriguing linear phenomenon in models that are initialized from a common pretrained checkpoint and finetuned on different tasks, termed as Cross-Task Linearity (CTL).
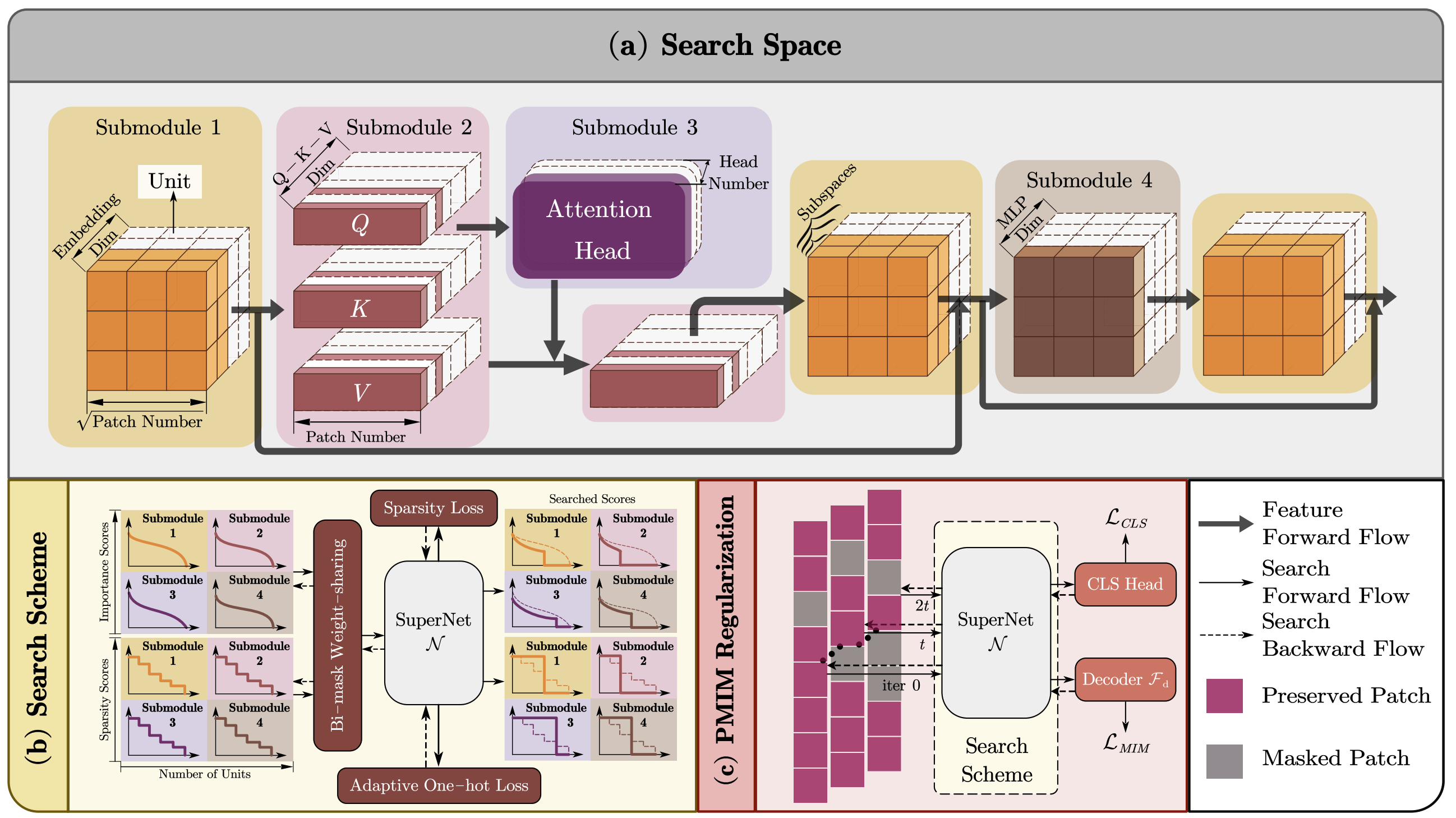
Once for Both: Single Stage of Importance and Sparsity Search for Vision Transformer Compression
Hancheng Ye, Chong Yu, Peng Ye, Renqiu Xia, Yansong Tang, Jiwen Lu, Tao Chen, Bo Zhang^(corr.)
- We investigate how to integrate the evaluations of importance and sparsity scores into a single stage, searching the optimal subnets in an efficient manner.
- We present OFB, a cost-efficient approach that simultaneously evaluates both importance and sparsity scores, termed Once for Both (OFB), for Vision Transformer Compression (VTC) task.
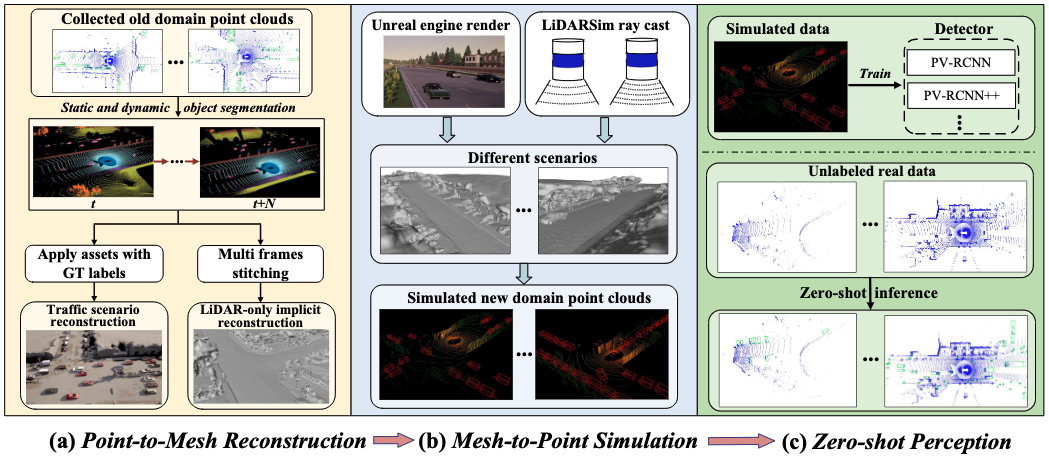
Bo Zhang, Xinyu Cai, Jiakang Yuan, Donglin Yang, Jianfei Guo, Xiangchao Yan, Renqiu Xia, Botian Shi, Min Dou, Tao Chen, Si Liu, Junchi Yan, Yu Qiao
- Provide a new perspective and approach of alleviating the domain shifts, by proposing a Reconstruction-Simulation-Perception scheme.
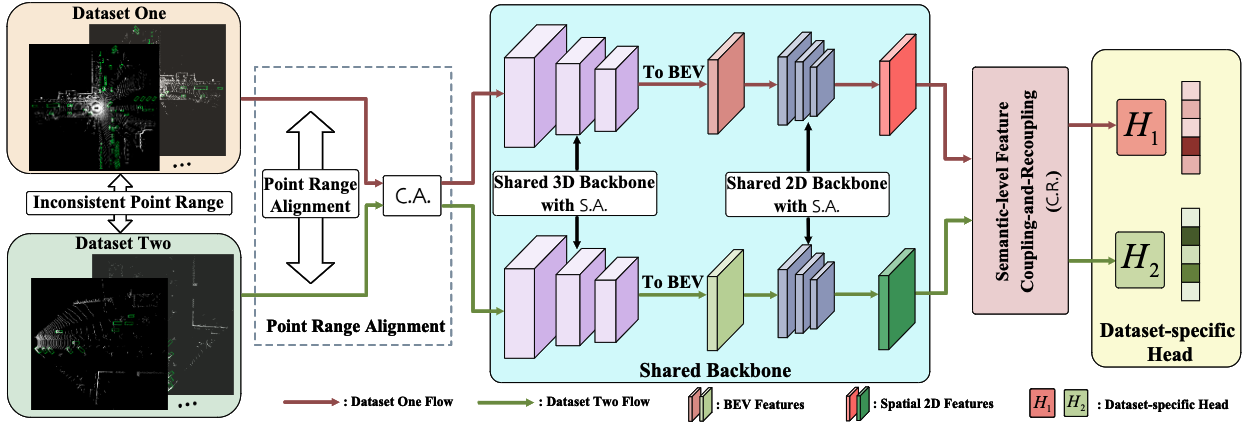
Uni3D: A Unified Baseline for Multi-dataset 3D Object Detection
Bo Zhang, Jiakang Yuan, Botian Shi, Tao Chen, Yikang Li, Yu Qiao
- Present a Uni3D which tackle multi-dataset 3D object detection from data-level and semantic-level.
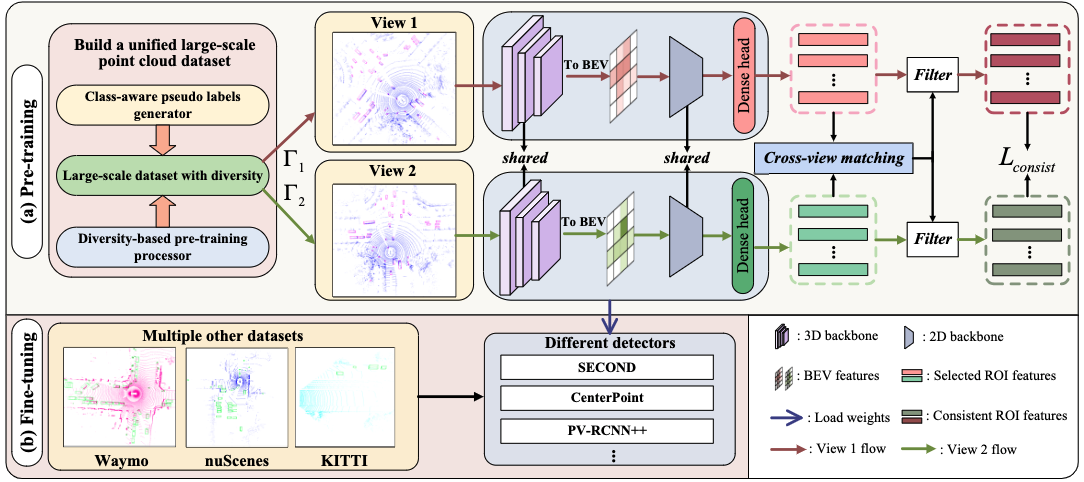
AD-PT: Autonomous Driving Pre-Training with Large-scale Point Cloud Dataset
Jiakang Yuan, Bo Zhang^(corr.), Xiangchao Yan, Tao Chen, Botian Shi, Yikang Li, Yu Qiao
- Build a large-scale pre-training point-cloud dataset with diverse data distribution, and meanwhile learn generalizable representations.
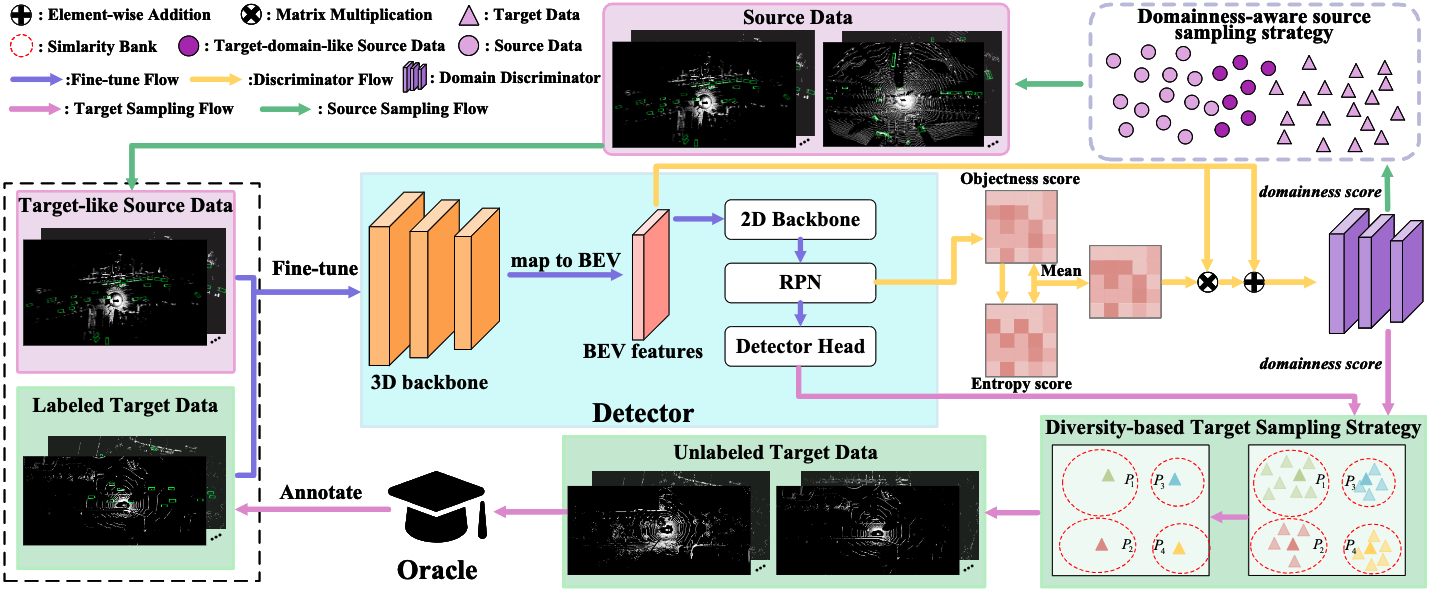
Bi3D: Bi-domain Active Learning for Cross-domain 3D Object Detection
Jiakang Yuan, Bo Zhang^(corr.), Xiangchao Yan, Tao Chen, Botian Shi, Yikang Li, Yu Qiao
- Propose a Bi-domain active learning approach which select samples from both source and target domain to solve the cross-domain 3D object detection task.
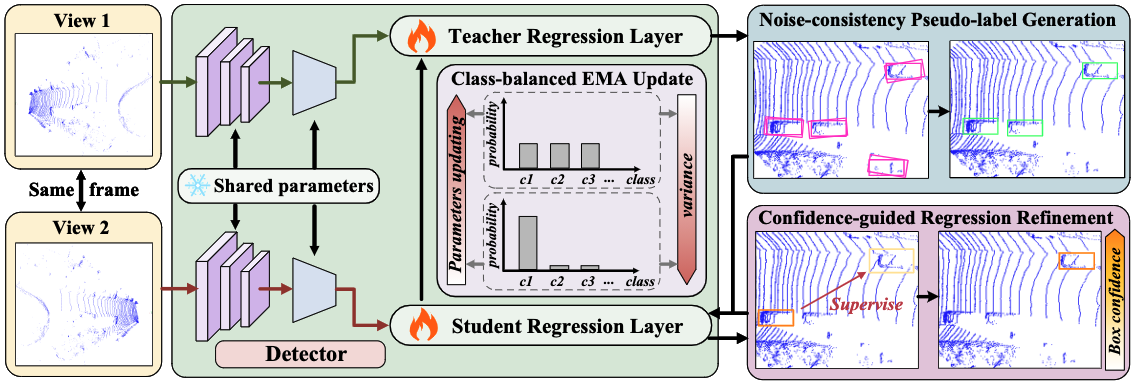
Reg-TTA3D: Better Regression Makes Better Test-time Adaptive 3D Object Detection
Jiakang Yuan, Bo Zhang, Kaixiong Gong, Xiangyu Yue, Botian Shi, Yu Qiao, Tao Chen
- Explore a new task named test-time domain adaptive 3D object detection and propose a pseudo-label-based test-time adaptative 3D object detection method.
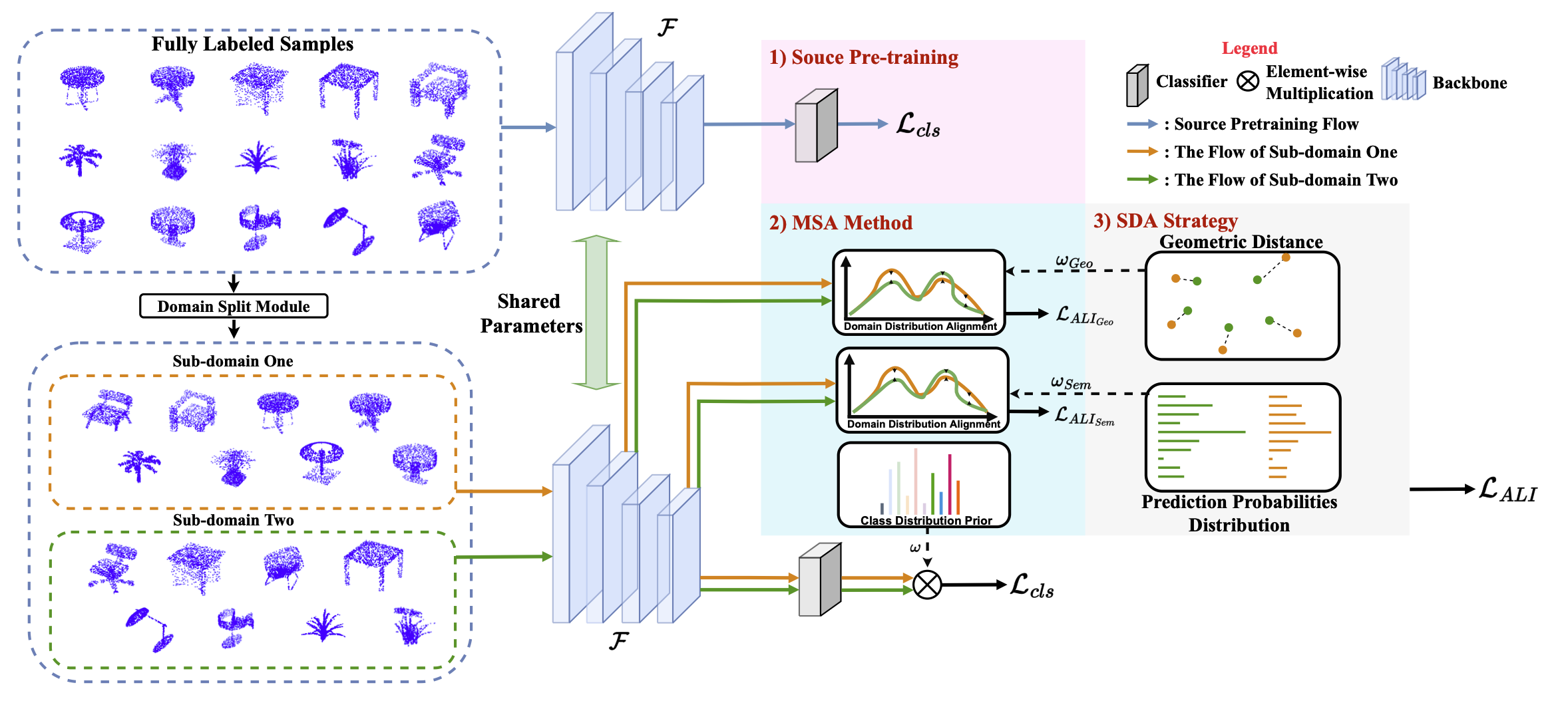
SUG: Single-dataset Unified Generalization for 3D Point Cloud Classification
Siyuan Huang, Bo Zhang^(corr.), Botian Shi, Peng Gao, Yikang Li, Hongsheng Li
- Propose a Single-dataset Unified Generalization (SUG) framework that only leverages a single source dataset to alleviate the unforeseen domain differences faced by a well-trained source model. .
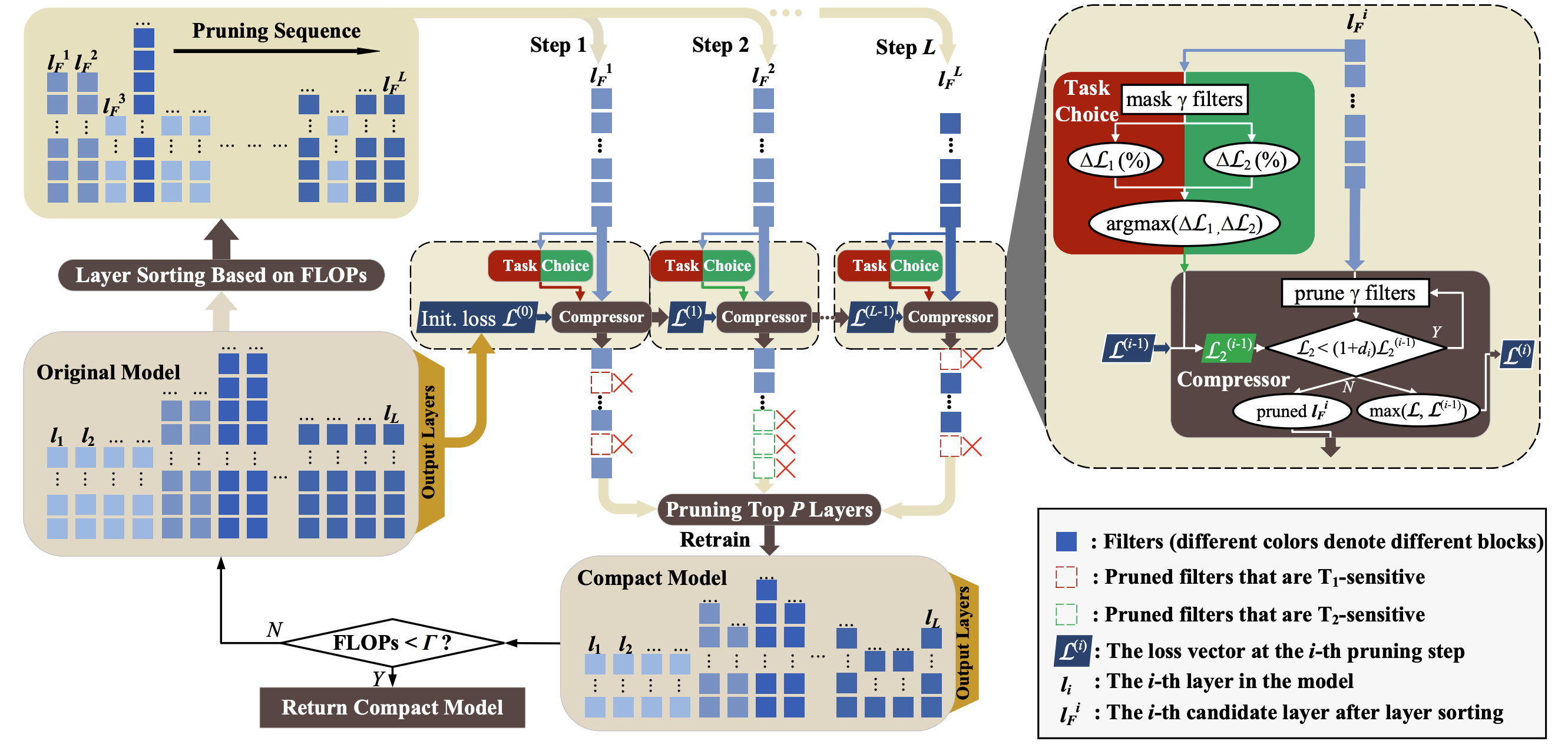
Performance-aware Approximation of Global Channel Pruning for Multitask CNNs
Hancheng Ye, Bo Zhang, Tao Chen, Jiayuan Fan, Bin Wang
- We propose a Performance-Aware Global Channel Pruning (PAGCP) framework. We first theoretically present the objective for achieving superior GCP, by considering the joint saliency of filters from intra- and inter-layers.
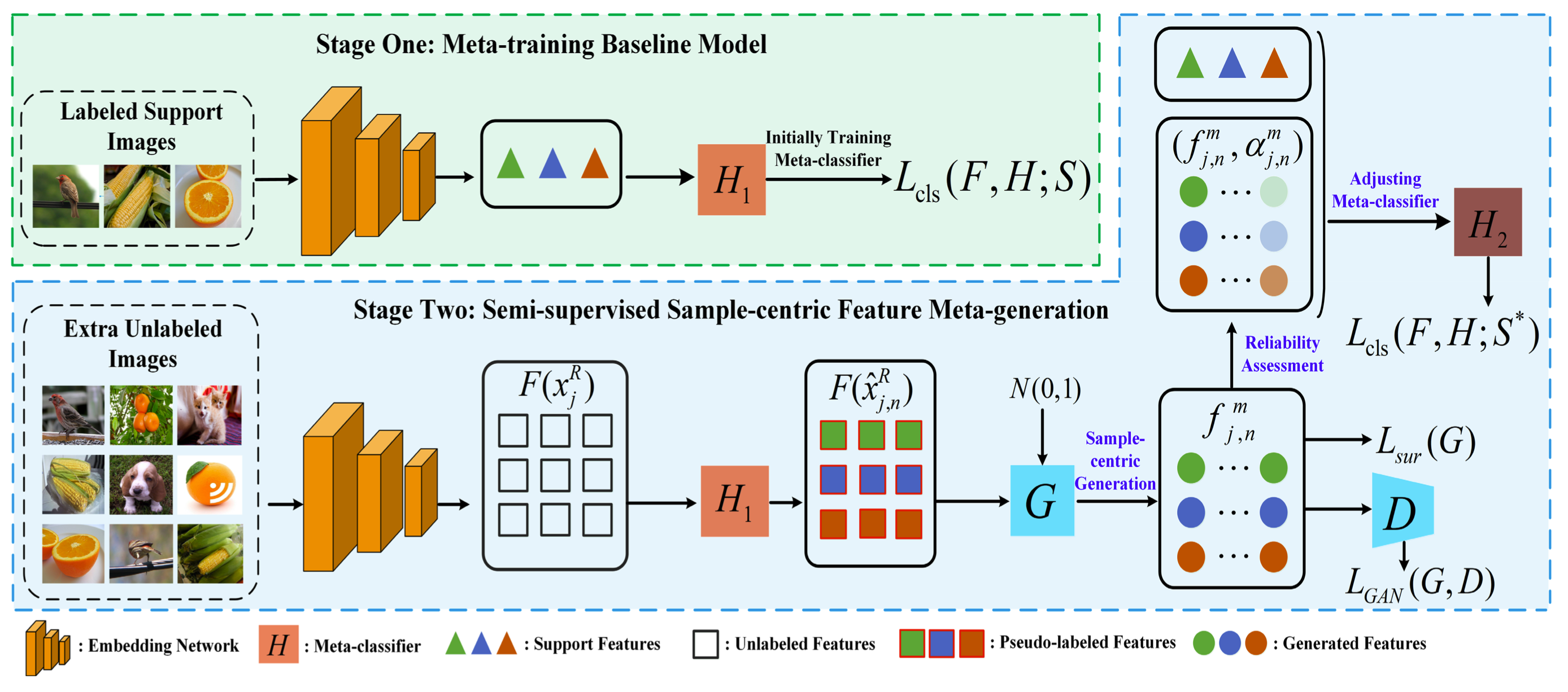
Sample-Centric Feature Generation for Semi-Supervised Few-Shot Learning
Bo Zhang, Hancheng Ye, Gang Yu, Bin Wang, Yike Wu, Jiayuan Fan, Tao Chen
- Propose a sample-centric feature generation (SFG) approach for semi-supervised few-shot image classification.
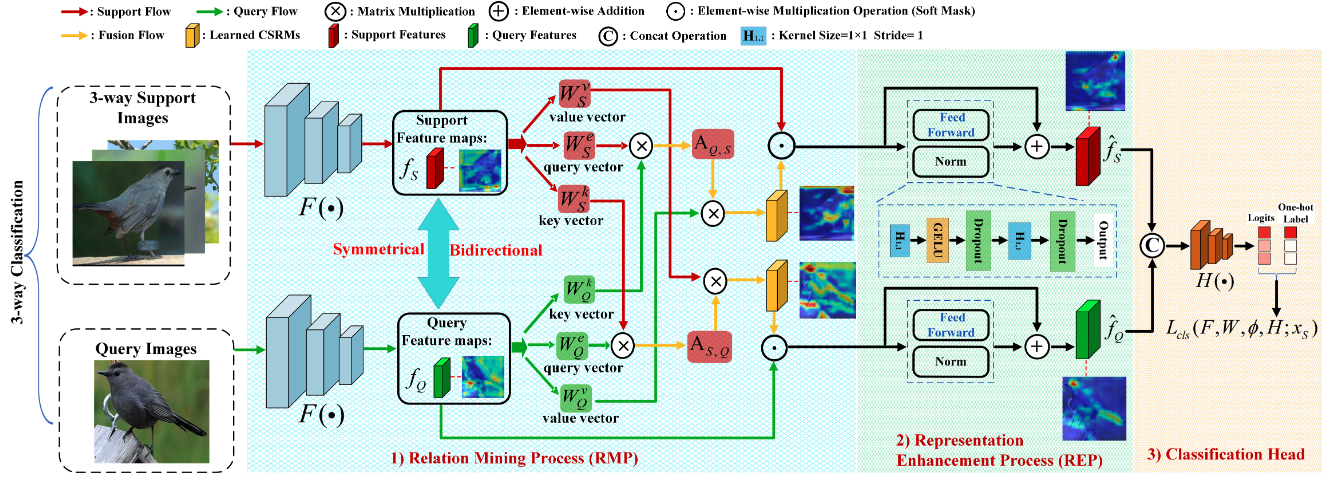
Bo Zhang, Jiakang Yuan, Baopu Li, Tao Chen, Jiayuan Fan, Botian Shi
- Propose a Transformer-based double-helix model to achieve the cross-image object semantic relation mining in a bidirectional and symmetrical manner.
💬 Invited Talks
- 2024.07, Invited talk of Multimodal Large Model Summit. [Video]
- 2023.09, Invited talk of Effcient Pre-training of Autonomous Driving. [Video]
- 2023.07, Invited talk of Towards 3D General Representation at Techbeat. [Video]
- 2023.03, Invited talk of Transferable Pwerception of Autonomous Driving. [Video]
💻 Internships
- 2021.12 - 2022.06, Shanghai AI Laboratory, China.